Golang爬虫入门系列(一)

0x0 读前tips
本文阅读前置需求:golang基本语法,html、css、js基础知识。听说过正则表达式和golang的http。
本文写作目的:记录一次极简爬虫脚本入门向开发。仅供学习使用,不可对网站造成损失。
0x1 初识爬虫
wiki:
网络爬虫(web crawler,spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引,如:
网络搜索引擎等站点通过爬虫软件更新自身的网站内容或其对其他网站的索引。网络爬虫可以将自己所访问的页面保存下来,以便搜索引擎事后生成索引供用户搜索。爬虫访问网站的过程会消耗目标系统资源。不少网络系统并不默许爬虫工作。因此在访问大量页面时,爬虫需要考虑到规划、负载,还需要讲“礼貌”。 不愿意被爬虫访问、被爬虫主人知晓的公开站点可以使用robots.txt文件之类的方法避免访问。这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理。
我目前的认识:爬虫可以访问网页,但获取到的内容和浏览器加载的内容不一定一样(涉及一些资源的加载),大多数网站都设置了基础的反爬,但是可以通过设置Headers的方式破解。
今日收获:复盘了极简爬虫的整体开发步骤。
TODO:
- 了解golang的http包
- 手搭爬虫大概框架,模块化整个项目
- 爬虫深入...
0x2 极简爬虫入门开发步骤
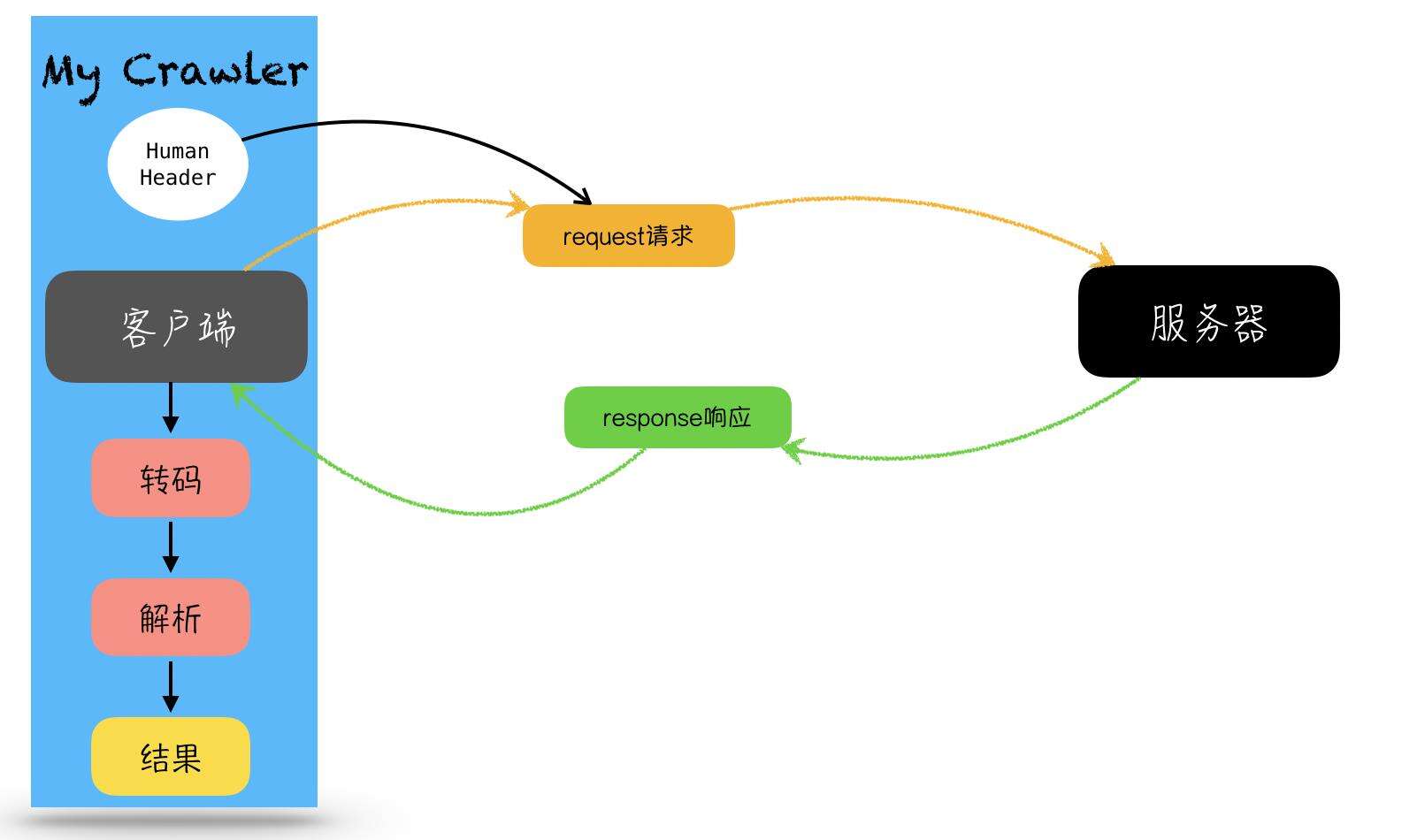
- 创建客户端
- 创建http request请求
- 为请求头添加Header
- 客户端发出请求request
- 客户端接收响应response
- 对response.Body进行解码分析,若不是utf-8,则转化为utf-8编码
- 对获取的内容进行解析:使用正则表达式提取所需信息,格式化输出
- 得到结果
如下图所示
0x03 代码 + 注释解析
如下:
package main
import (
"bufio"
"fmt"
"golang.org/x/net/html/charset"
"golang.org/x/text/encoding"
"golang.org/x/text/transform"
"io"
"io/ioutil"
"log"
"net/http"
"regexp"
)
func main() {
url := "https://www.bilibili.com/v/popular/rank/all"
// 创建客户端
client := &http.Client{}
// 创建request请求
req, err := http.NewRequest("GET", url, nil)
if err != nil {
log.Fatalln(err)
}
// 设置Header
req.Header.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36")
// 客户端发起请求,收到响应
resp, err := client.Do(req)
if err != nil {
log.Fatalln(err)
}
defer resp.Body.Close()
// 如果访问失败,就打印当前状态码
if resp.StatusCode != http.StatusOK {
fmt.Println("Error: status code", resp.StatusCode)
return
}
// 需要得到获取的内容的编码
e := determineEncodeing(resp.Body)
// 得到utf-8编码的内容
utf8Reader := transform.NewReader(resp.Body, e.NewDecoder())
// 读取网页所有信息
all, err := ioutil.ReadAll(utf8Reader)
if err != nil {
panic(err)
}
// 打印信息
fmt.Printf("%s",all)
//对获取的内容进行解析和打印
printTitle(all)
}
func determineEncodeing(r io.Reader) encoding.Encoding {
bytes, err := bufio.NewReader(r).Peek(1024)
if err != nil {
panic(err)
}
e, _, _ := charset.DetermineEncoding(bytes, "")
return e
}
func printTitle(contents []byte) {
// 正则表达式,用于匹配内容,+代表至少含有一个内容,^表示不可以含有的内容,加括号的地方会取到数组里
re := regexp.MustCompile(`<a href="//(www.bilibili.com/video/[0-9a-zA-Z]+)" target="_blank" class="title">([^<]+)</a>`)
// -1 寻找所有匹配的字串
matches := re.FindAllSubmatch(contents, -1)
// 打印
for _, m := range matches {
fmt.Printf("Title: %s, URL:%s\n", m[2], m[1])
}
fmt.Printf("matches: %d\n", len(matches))
}
0x04 结语
今天没什么灵感,也没耐心,荒废两个半小时。以后有精力会继续补充。